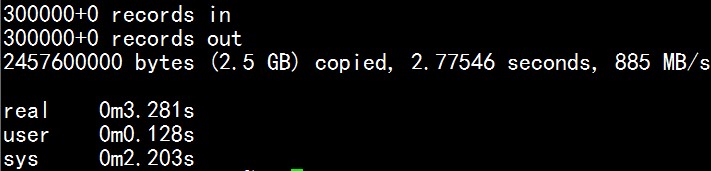
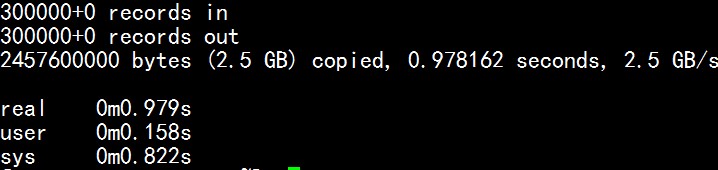
在内网中建立yum服务器,内网linux服务器可以使用yum升级。这样做有两个好处,一内网服务器不用登陆公网比较安全,二节约了流量,不用每台服务器更新都连到公网上。
安装配置比较简单。需要nginx或apache,本次只列出了nginx配置。还需要rsync工具,建议使用命令“yum install -y rsync”。
yum服务器内网地址192.168.100.100
Nginx配置
#######################################yum server
server {
# 直接使用IP地址
server_name 192.168.100.100;
# 开启自动显示目录
autoindex on;
# 显示文件大小
autoindex_exact_size off;
# 显示服务器本地时间
autoindex_localtime on;
# yum放置目录
root /u01/yumserver/;
# 内网可见
allow 192.168.100.0/24;
# 除上列ip均不能查看
deny all;
# 限制ip后会报403错误,做个跳转
error_page 400 403 404 500 502 503 504 = http://www.simonzhang.net;
}
同步脚本,将脚本有可执行权限,将此设置到crontab即可。
#!/bin/bash
# -------------------------------
# Revision:
# Date: 2012-12-11
# Author: simonzhang
# Email: simon-zzm@163.com
# Web: www.simonzhang.net
# -------------------------------
# base value
# 要同步的源
YUM_SITE="rsync://mirrors.kernel.org/centos/"
# 本地存放目录
LOCAL_PATH="/u01/mirrors/centos/"
# 需要同步的版本,我只需要5和6版本的
LOCAL_VER="5 5* 6 6*"
# 同步时要限制的带宽
BW_limit=512
# 记录本脚本进程号
LOCK_FILE="/var/log/yum_server.pid"
# 如用系统默认rsync工具为空即可。
# 如用自己安装的rsync工具直接填写完整路径
RSYNC_PATH=""
# check update yum server pid
MY_PID=$$
if [ -f $LOCK_FILE ]; then
get_pid=`/bin/cat $LOCK_FILE`
get_system_pid=`/bin/ps -ef|grep -v grep|grep $get_pid|wc -l`
if [ $get_system_pid -eq 0] ; then
echo $MY_PID>$LOCK_FILE
else
echo "Have update yum server now!"
exit 1
fi
else
echo $MY_PID>$LOCK_FILE
fi
# check rsync tool
if [ -z $RSYNC_PATH ]; then
RSYNC_PATH=`/usr/bin/whereis rsync|awk ' ''{print $2}'`
if [ -z $RSYNC_PATH ]; then
echo 'Not find rsync tool.'
echo 'use comm: yum install -y rsync'
fi
fi
# sync yum source
for VER in $LOCAL_VER;
do
# Check whether there are local directory
if [ ! -d "$LOCAL_PATH$VER" ] ; then
echo "Create dir $LOCAL_PATH$VER"
`/bin/mkdir -p $LOCAL_PATH$VER`
fi
# sync yum source
echo "Start sync $LOCAL_PATH$VER"
$RSYNC_PATH -avrtH --delete --bwlimit=$BW_limit --exclude "isos" $YUM_SITE$VER $LOCAL_PATH$VER
done
# clean lock file
`/bin/rm -rf $LOCK_FILE`
echo 'sync end.'
exit 1
centos_yum_server
客户端配置
编辑/etc/yum.repos.d/CentOS-Base.repo
#base
[base]
name=CentOS-$releasever – Base
baseurl=http://192.168.100.100/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
#released updates
[updates]
name=CentOS-$releasever – Updates
baseurl=http://192.168.100.100/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
#additional packages that may be useful
[extras]
name=CentOS-$releasever – Extras
baseurl=http://192.168.100.100/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever – Plus
baseurl=http://192.168.100.100/centos/$releasever/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
#contrib – packages by Centos Users
[contrib]
name=CentOS-$releasever – Contrib
baseurl=http://192.168.100.100/centos/$releasever/contrib/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6