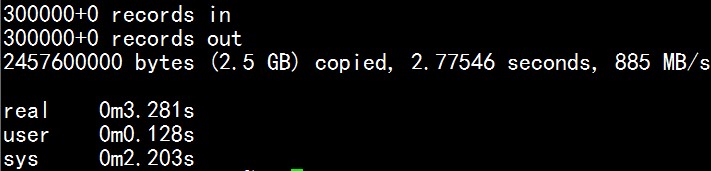
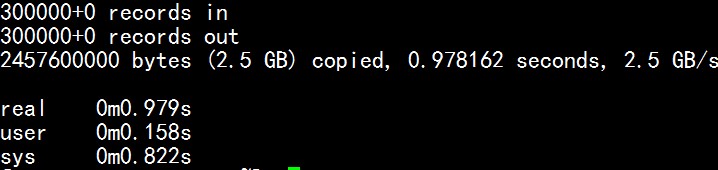
需要对android的一个软软件做个疲劳测试,使用android SDK自带的工具最为方便。所就开始做monkey测试,调用和回播的脚本是从网上搜集而来,自己做了小修改。原始脚本的网页url忘记记录,所以不能提供参考网连接。下面开始对我所做的简单测试做个记录。
首先是在系统上安装java运行环境,这个比较简单。下载android SDK包,直接解压后就可以使用非常方便。
进入android-sdk-windows/tools目录,在其下面写两个脚本。
录脚本的启动脚本名monkey_recorder.py脚本内容如下:
#!/usr/bin/env monkeyrunner
# Copyright 2010, The Android Open Source Project
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from com.android.monkeyrunner import MonkeyRunner as mr
from com.android.monkeyrunner.recorder import MonkeyRecorder as recorder
device = mr.waitForConnection()
recorder.start(device)
回放脚本名为monkey_playback.py脚本内容如下:
#!/usr/bin/env monkeyrunner
# Copyright 2010, The Android Open Source Project
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import sys
from com.android.monkeyrunner import MonkeyRunner
# The format of the file we are parsing is very carfeully constructed.
# Each line corresponds to a single command. The line is split into 2
# parts with a | character. Text to the left of the pipe denotes
# which command to run. The text to the right of the pipe is a python
# dictionary (it can be evaled into existence) that specifies the
# arguments for the command. In most cases, this directly maps to the
# keyword argument dictionary that could be passed to the underlying
# command.
# Lookup table to map command strings to functions that implement that
# command.
CMD_MAP = {
'TOUCH': lambda dev, arg: dev.touch(**arg),
'DRAG': lambda dev, arg: dev.drag(**arg),
'PRESS': lambda dev, arg: dev.press(**arg),
'TYPE': lambda dev, arg: dev.type(**arg),
'WAIT': lambda dev, arg: MonkeyRunner.sleep(**arg)
}
# Process a single file for the specified device.
def process_file(fp, device):
for line in fp:
(cmd, rest) = line.split('|')
try:
# Parse the pydict
rest = eval(rest)
except:
print 'unable to parse options'
continue
if cmd not in CMD_MAP:
print 'unknown command: ' + cmd
continue
CMD_MAP[cmd](device, rest)
def go(file,num):
n = num
device = MonkeyRunner.waitForConnection()
for i in range(int(n)):
print 'now %s'%i
fp = open(file, 'r')
process_file(fp, device)
fp.close();
def main():
file = sys.argv[1]
try :
number = sys.argv[2]
except :
number = 1
go(file,number)
if __name__ == '__main__':
main()
到此环境和脚本就算部署完了。下面开始记录脚本使用。
首先将手机和电脑用usb线连好,使用“cmd”调出命令行,然后进入“android-sdk-windows/tools”目录。输入命令:
monkeyrunner.bat monkey_recorder.py
如果没有报错,并且出现以下界面,就可以开始录制脚本了。

“wait”为每步操作间的等待时间。“Press a Button“发送,MENU,HOME,or SEARCH 按钮。“Type Something”为输入文字。“Fling”为模拟滑动操作。“Export Actions”为保存刚才录制的脚本。最后一个为刷新。
保存的脚本可以直接用文本编辑器手动编辑。假如我们录制的脚本为text.txt。下一步就是回放脚本,使用命令为:
monkeyrunner.bat monkey_playback.py test.txt 100
最后的数字是将这个脚本循环100次。
我只需要到此即可了。如果需要抓图片\照相\判断等高级功能,将来需要时再学习。